
VerificAudio es una herramienta para que los periodistas detecten deepfakes creados con voces sintéticas en español. Fue creado por el grupo de medios español PRISA Media, el mayor productor de audio en español a nivel mundial, con más de 30 marcas de radio en España, Colombia, Chile y México. En un artículo que publicamos hoy, la gerente de producto Olalla Novoa explica cómo ella y sus colegas crearon esta herramienta experimental y qué otras redacciones pueden aprender de este proceso.
Una cita. “Cuando nuestros periodistas encuentran un archivo de audio sospechoso, lo envían al equipo de verificación, que luego trabaja con el reportero para evaluar el archivo, su origen, los canales en los que se compartió, su contexto noticioso y cualquier audio similar disponible. , así como el análisis de IA realizado con VerificAudio”, escribe Novoa, quien explica que también están creando un repositorio doble: uno con archivos de audio verificados de personajes conocidos y otro con archivos de audio falsos para seguir entrenando a sus modelos.
1. El proyecto en pocas palabras
VerificAudio es una herramienta para que periodistas verifiquen audio y detecten deepfakes creados con voces sintéticas en español. Nuestro objetivo no es sólo brindar apoyo a los reporteros y editores de nuestras estaciones de radio, sino también reforzar la confianza de los oyentes frente a la desinformación.
En PRISA Media creemos que este será uno de los retos clave a los que se enfrentará la audiencia con el auge de la IA generativa. Somos la mayor productora de audio en español a nivel mundial, con más de 30 marcas de radio líderes en España, Colombia, Chile y México, y hemos creado una profunda relación de confianza con nuestros oyentes durante muchas décadas. En este nuevo ecosistema donde la clonación de voces puede convertirse en un arma, creemos que es nuestra responsabilidad fortalecer esta relación con el desarrollo de una herramienta que ayude a nuestros periodistas a verificar cualquier audio sospechoso.
2. El problema que queríamos resolver
Empezamos a trabajar con voces sintéticas en 2022. Nuestro primer experimento fue Victoria, la voz del fútbol , un asistente virtual para parlantes inteligentes. Desde entonces, hemos visto cómo las tecnologías de clonación de voz mejoran su calidad y velocidad de procesamiento. También han surgido como software de código abierto e incluso como servicios en línea. Esto hace que sea fácil y económico generar una réplica creíble de la voz de cualquier persona en cuestión de minutos.
Es por eso que audios falsos se han colado en plataformas de redes sociales y en aplicaciones de mensajería como Telegram o WhatsApp, utilizadas por millones de hispanohablantes en todo el mundo. Lo que comenzó como una sátira que utilizaba las voces de celebridades para bromas o fines cómicos se ha convertido rápidamente en una amenaza real a la confianza en las noticias y en la esfera pública en general.
Un par de ejemplos recientes fueron las infames llamadas automáticas falsas de Joe Biden y los audios falsos que parecían mostrar al alcalde de Londres, Sadiq Khan, haciendo comentarios incendiarios antes del Día del Armisticio.
También podríamos enfrentar el problema opuesto: personas poderosas que afirman falsamente que han clonado sus voces después de haber sido sorprendidas en situaciones embarazosas.
Estos son los problemas que queríamos abordar y queríamos abordarlos rápidamente cuando el mundo entró en este año de elecciones , con el audio generado por IA amenazando con convertirse en una fuente potencial de desinformación en países como México y España.
3. Cómo encontramos una solución
Con todos estos problemas en mente, comenzamos a trabajar en una plataforma de verificación de datos de audio que ayudaría a los periodistas en su búsqueda de verificar cualquier audio dudoso.
El proyecto fue impulsado por la Iniciativa Google News como parte de un esfuerzo para combatir la desinformación, compartir recursos y construir un ecosistema de noticias diverso e innovador. Concebido inicialmente como un proyecto de Caracol Radio (la unidad de radio de PRISA Media en Colombia), VerificAudio ha sido desarrollado por Minsait , una empresa tecnológica española con operaciones en más de 100 países. Plaiground , la unidad de negocio de IA de Minsait, utilizó procesamiento del lenguaje natural (NLP) y aprendizaje profundo para evaluar cualquier manipulación de audio.
Antes de que los algoritmos de aprendizaje automático puedan extraer información significativa del audio, es esencial preparar y normalizar los archivos de audio, mejorar la calidad de los datos y reducir la variabilidad no deseada que podría interferir con el proceso de entrenamiento del modelo. Nuestra herramienta realiza este trabajo a través de un proceso que incluye reducción de ruido, reconversión de formato, ecualización de volumen y recorte temporal.
Una vez que nuestro conjunto de datos estuvo listo y después de un exhaustivo proceso algorítmico de evaluación y selección, nos conformamos con dos enfoques complementarios: redes neuronales y un modelo basado en aprendizaje automático.
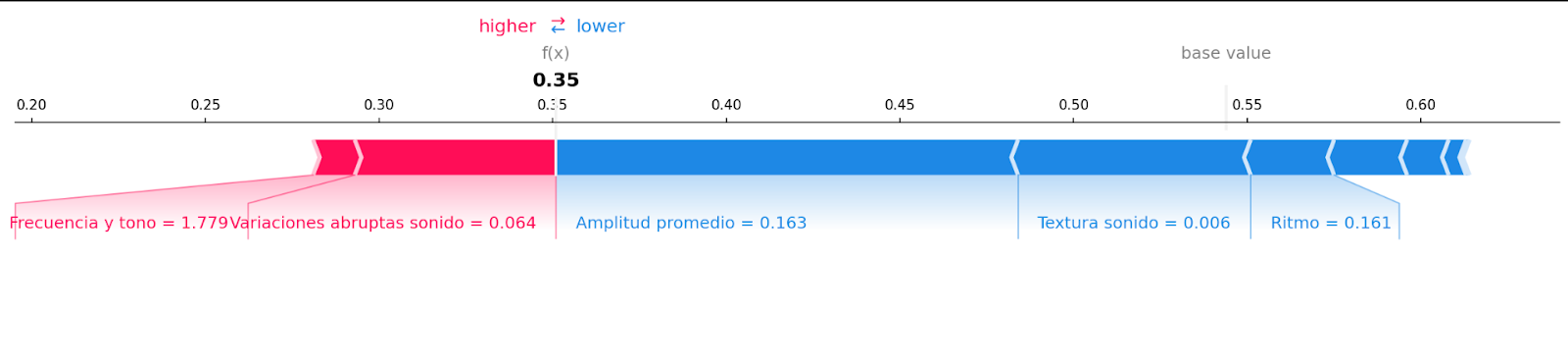
Para nuestro modelo de aprendizaje automático, el equipo de Plaiground analizó qué características de audio (las propiedades físicas que se extraen de una señal de audio) tenían un mayor impacto en la predicción realizada por el modelo de IA. Los ingenieros de Plaiground también definieron un conjunto de KPI que luego les permitirían validar los resultados y confirmar que el modelo era correcto al detectar deepfakes y minimizar el número de falsos positivos. En este modo de identificación individual, un gráfico de explicabilidad (ver captura de pantalla a continuación) muestra la importancia y el peso de cada una de las características de audio, lo que permite a los usuarios comprender qué aspectos del audio influyen más en la predicción de nuestro modelo.
Al mismo tiempo, seguimos el enfoque de redes neuronales, ajustando un modelo de código abierto existente y adaptándolo al idioma español. Este enfoque compara dos audios y determina si son de la misma persona, de dos personas diferentes o si han sido generados mediante un proceso sintético. El modelo convierte cada audio en un vector de características que representa las peculiaridades únicas de la voz, capturando aspectos como el tono, la entonación y los patrones del habla. Luego compara cada par de vectores.
Decidimos mantener ambos modelos (aprendizaje automático y redes neuronales) como parte de nuestra caja de herramientas, implementando un protocolo de doble verificación para aumentar la precisión y minimizar la cantidad de resultados falsos. Paralelamente, desarrollamos una interfaz en línea para simplificar cualquier prueba realizada por personas no técnicas.
4. Los problemas que encontramos
Creemos que los deepfakes de audio van a ganar terreno en los próximos meses, pero a estas alturas es difícil compilar un gran corpus de audios falsos en español. Intentamos encontrar ejemplos en las redes sociales. Pero al final del día, terminamos generando nuestro propio conjunto de datos utilizando diferentes tecnologías de clonación disponibles en el mercado e imitando audios falsos reales que habíamos encontrado en nuestra búsqueda.
Nuestros compañeros de Caracol Radio en Colombia jugaron un papel fundamental en este proceso, aportando audios de nuestros propios archivos y nuevos audios generados por personas del equipo. Dado que nuestros modelos se centran en características y patrones de audio, y no en la longitud de cada archivo de audio, podríamos dividir algunos de los archivos más largos para multiplicar nuestro conjunto de datos con fines de entrenamiento.
Este es un proyecto en curso y requerirá perfeccionar constantemente nuestros modelos y considerar nuevas tecnologías de clonación y nuevas formas de producir audios falsos que eventualmente surgirán.
Cuando se trabaja con IA, dos obstáculos comunes son la trazabilidad y la explicabilidad. Los grandes modelos neuronales funcionan como una caja negra: te ofrecen resultados, pero no te dan ningún elemento para interpretar cómo llegaron a esos resultados. Por eso creemos que es importante tener un proceso de dos vertientes, en el que nuestro modelo de aprendizaje automático indique qué atributos de audio tuvieron un papel importante en una decisión.
5. Cómo probamos nuestra herramienta
Validar los resultados significa ver qué tan confiables son si los comparas con el juicio humano. Para probar nuestros modelos, compilamos un nuevo conjunto de datos de audios reales y falsos para probar ambos modelos tanto mecánica como manualmente. Este enfoque dual, que combina el poder de la inteligencia artificial con la experiencia humana, nos ayudó a garantizar una evaluación más precisa y completa de la capacidad de la plataforma para detectar manipulaciones de audio.
Este proceso no solo nos ayudó a identificar resultados inexactos. También nos permitió volver a entrenar y perfeccionar nuestros modelos, y nos brindó información clave para mejorar nuestra interfaz de usuario y hacerla más accesible. El proceso también nos hizo conscientes de la dificultad de clasificar los resultados y de la necesidad de considerar un enfoque probabilístico que ayude al periodista a tomar una decisión. A la hora de detectar deepfakes no es viable ofrecer resultados absolutos, sino una tendencia hacia lo real o lo falso. En VerificAudio, esto se traduce en un porcentaje que orienta a los periodistas, quienes deben tomar una decisión final dentro de sus propios procesos de fact-checking.

6. Cómo funciona la herramienta en la práctica
Nuestra interfaz VerificAudio ya es accesible para todos los equipos de verificación en las emisoras de radio de PRISA Media en España, Colombia, México y Chile. Creemos que la IA es solo una herramienta y de ninguna manera reemplaza los protocolos de verificación de datos actuales.
Cuando nuestros periodistas encuentran un archivo de audio sospechoso, lo envían al equipo de verificación, que luego trabaja con el reportero para evaluar el archivo, su origen, los canales de distribución en los que se compartió, su contexto noticioso y cualquier audio similar disponible. , así como el análisis de IA realizado con VerificAudio. También estamos creando un repositorio doble: uno con archivos de audio verificados de figuras conocidas que agiliza el proceso de comparación, y otro con archivos de audio falsos que usaremos para seguir entrenando nuestros modelos.
La interfaz de VerificAudio es simple y fácil de usar. Permite a los usuarios cargar un archivo de audio sospechoso y un archivo de audio real de la misma persona y verificar los resultados del análisis. Los usuarios pueden elegir entre dos opciones de verificación diferentes: modo comparativo y modo de identificación.
En modo comparativo, VerificAudio les mostrará si los archivos pertenecen al mismo locutor, a diferentes locutores o a una voz clonada. En modo de identificación, la herramienta indicará si el archivo de audio ingerido es probable que sea real o sintético ofreciendo un coeficiente y una lista de los principales atributos tenidos en cuenta en el resultado.
7. Cómo se puede mejorar la herramienta
VerificAudio ha sido concebido como una herramienta en constante evolución y deberá actualizarse a medida que surjan nuevas tecnologías. Nuestro objetivo es seguir ampliando la diversidad del conjunto de datos para el reentrenamiento de modelos, refinando sus resultados e incluyendo muestras cada vez más grandes de deepfakes.
Seguiremos mejorando nuestra muestra teniendo en cuenta diferentes acentos españoles de todo el mundo. En el futuro nos gustaría poder ampliar el alcance de la herramienta a otras lenguas de España como el catalán, el euskera o el gallego.
Paralelamente, estamos mejorando nuestra herramienta para ampliar el acceso y desarrollando una plataforma en línea donde podamos publicar los análisis realizados por nuestras redacciones. Este sitio incluirá recursos educativos para que nuestra audiencia pueda aprender sobre los deepfakes.
8. Cómo esto puede ayudar a otras redacciones
Por ahora, VerificAudio es sólo un recurso interno que se utilizará dentro de las redacciones de PRISA Media. Nuestros equipos de verificación también analizarán los audios que cualquiera envíe a través del sitio del proyecto .
Creemos que la plataforma web que estamos desarrollando también desempeñará un papel importante a la hora de proporcionar una visión general del panorama de la verificación de audio deepfake, y no descartamos abrir el acceso a otras empresas de medios en el futuro una vez que la herramienta haya sido mejorada y ampliada.
Fuente; Reuters Institute




































